테이블 구조
- 관계형 데이터베이스 관리 시스템(RDBMS)의 가장 기본적인 데이터 저장 구조
- 하나 이상의 열과 0개 이상의 행으로 구성

테이블의 물리적 구조 = 파일file
- 레코드가 순차적으로(혹은 정렬되어) 있는 것
테이블 레코드
- 관련된 데이터 값value(혹은 항목item)의 모음
- 해당 값들은 레코들의 특정 필드field(혹은 속성attribute)에 대응
테이블 레코드 포맷 (메타데이터)
- 필드 이름과 대응하는 데이터 타입의 모음으로 구성
- 데이터 타입: 수치형, 문자열, 불리언, 날짜/시간 등
- 값들은 레코드 필드(혹은 속성, 열)에 대응
- 데이터 베이스 언어(SQL)를 이용한 레코드 포맷 설정 방법: 데이터 정의 언어(DDL)을 사용
테이블 레코드 종류
1. 고정 길이 레코드: 파일에 있는 모든 레코드의 길이가 동일한 레코드
2. 가변 길이 레코드: 파일에 있는 레코드의 길이가 서로 다른 레코드
테이블 생성 방법
- SQL문(create table)을 사용하여 데이터베이스 설계 단계에서 생성한 관계형 테이블 설계를 실제로 구현할 수 있음

테이블 삭제 방법
- SQL문(drop table)을 사용하여 생성한 테이블(데이터, 조건)을 삭제할 수 있음
- 테이블의 구조와 데이터를 모두 삭제하기 때문에 사용에 주의

테이블 변경(추가, 수정, 삭제) 방법
- SQL문(alter table)을 사용하여 생성한 테이블의 정보(열, 제약조건)를 변경할 수 있음

테이블 삽입 방법
- SQL문(insert)을 사용하여 해당 테이블에 정의된 각 열의 타입에 속하는 값을 순서대로 기술하여 삽입

레코드 조회 방법
- SQL문(select)을 사용하여 해당 테이블에 저장된 레코드를 찾음

레코드 갱신 방법
- SQL문(update)을 사용하여 특정한 열의 값을 수정

레코드 삭제 방법
- SQL문(delete)을 사용하여 특정한 행(0개 이상)을 삭제

데이터베이스 인덱스 구조: 데이터베이스의 물리적 저장

- 데이터 파일: 물리적으로 존재, 테이블과 인덱스로 구성
데이터베이스 인덱스 구조: 도서의 색인
- 도서의 색인 = 어떤 단어를 사용한 페이지를 빨리 찾아볼 수 있도록 어떤 단어와 그 단어가 언급된 페이지 번호를 기록해 놓은 페이지, 색인된 단어는 일반적으로 오름차순으로 정렬
데이터베이스 인덱스 구조: 데이터베이스 인덱스 개념/필요성
- 개념: 데이터베이스에서 테이블 필드의 특정 값을 가지고 있는 레코드를 테이블의 모든 레코드를 살펴보지 않고도 효과적으로 찾을 수 있는 자료 구조, 레코드 검색을 수행할 때 디스크 블록을 읽는 횟수를 줄이기 위해 특수하게 설계
- 필요한 이유: 테이블 레코드 검색 시 디스크 블록의 접근 횟수 최소화 필요, 메인메모리(RAM)에 있는 데이터를 읽어들이는 속도보다 디스크에 있는 데이터를 읽어들이는 속도가 거의 10000배 정도 더 소요되기 때문에

- 특징: 인덱스는 테이블에서 한 개 이상의 속성을 이용해 생성, 빠른 검색을 지원하며 효율적인 레코드(행) 접근이 가능, 순서대로 "정렬된 속성(필드, 보통 키) 값, 테이블 레코드의 위치값"만 보유, 테이블 데이터보다 훨씬 작은 공간만 차지, 저장된 값들은 테이블 데이터의 부분집합이라고 볼 수 있음, 데이터의 수정, 삭제 등의 변경이 발생하면 인덱스 재구축이 필요할 수도 있음
인덱스를 경유한 레코드 접근

- 인덱스 블록을 먼저 메모리에 읽어 들임
- 해당 인덱스 블록으로부터 전체 데이터 블록 중 요청된 데이터 블록의 정보를 탐색
- 해당 데이터 블록을 메모리로 읽어들임
- 이점: 전체 데이터 블록을 다 읽을 필요가 없이 요청한 데이터 블록만 효율적으로 접근할 수 있도록 가능
데이터베이스 인덱스 구조: B+트리 구조
- 보통 B+트리 구조 사용 (B: Balanced)

데이터베이스 인덱스 구조: 인덱스 관리 지침
- 인덱스 관리 시 주의사항
1. 테이블 레코드 삽입 후 인덱스를 생성
2. 올바른 테이블과 열을 인덱스화
3. 인덱스는 질의문의 조건절(즉 where절)에 자주 사용되는 속성일 것
4. 인덱스는 테이블 조인에 자주 사용되는 속성일 것
5. 성능 보장을 위해 인덱스 열의 순서를 지정
6. 단일 테이블에 너무 많은 인덱스가 있으면 성능저하가 일어날 수 있음 (테이블당 4~5개 정도를 권장)
7. 더 이상 필요하지 않은 인덱스를 삭제
8. 속성이 자주 변경될 경우 사용하지 않음
9. 인덱스 병합 또는 재구축의 비용과 이점을 고려
데이터베이스 관리 시스템 (DBMS)
- 사용자가 데이터베이스를 생성하고 유지할 수 있도록 해주는 소프트웨어 패키지 및 시스템

데이터베이스 시스템
- DB + DBMS + DB 응용 프로그램
데이터베이스 인터페이스
1. 독립형 (질의 언어) 인터페이스
- 콘솔에서 직접 데이터베이스와 연결
2. 사용자 친화적인 그래픽 유저 인터페이스
- 메뉴기반, 폼기반, 그래픽기반 인터페이스로 데이터베이스와 연결
3. 프로그래머 인터페이스
- 일반 프로그래밍 언어에 데이터 조작 언어를 탑재하여 DBMS와 연결, 내장방법(Embedded SQL), 프로시저 호출방법(JDBC/ODBC), DB 프로그래밍 언어 방법(PL/SQL), 스크립팅 방법(PHP/Python)
4. 모바일 인터페이스
- 모바일 앱 페이지 인터페이스로 DBMS와 연결
5. 웹 기반 인터페이스
- 인터넷 뱅킹 등
6. 자연어 처리 인터페이스
- 최신 기법, 자유 텍스트를 질의어로 사용
7. 음성 인터페이스 등
데이터베이스 언어
1. DDL
- 데이터 정의 언어: 데이터베이스의 개념/내부 스키마 및 그들 간의 연결을 지시하기 위한 언어
2. DML
- 데이터 조작 언어: 데이터 검색 및 갱신을 지시하기 위한 언어
DML의 유형
1. 높은 수준의 (혹은 비절차적) 언어
- 원하는 데이터를 어떻게 찾아오라고 지시하지 않고 어떤 데이터가 필요한지만 기술, 선언적
2. 낮은 수준의 (혹은 절차적) 언어
- 절차를 기술, 반드시 프로그래밍 언어에 탑재되어야 함, 절차적
- SQL 언어는 선언적인 언어 (사용하기 편리)
SQL
- Structured Query Language
- 처음에 SQUARE 언어로 제안
- 튜플 해석(관계형 술어)에서 유래
- 원래 이름은 SEQUEL
- SYSTEM R이라는 실험적인 관계형 데이터베이스 관리 시스템의 인터페이스로 IBM 연구소에서 설계 및 구현 (IBM은 이후 SQL이라는 용어를 저작권으로 보호)
- 현재 모든 RDBMS의 표준언어로 채택되어 사용 중
- 관계형 데이터 모델을 어려운 정형 언어가 아닌 실제적으로 표현해 낼 수 있다는 점에서 쉽게 접할 수 있는 인기 언어

일반 프로그래밍 언어와 SQL의 차이점

SQL로 표현되는 관계형 데이터베이스 실무에서 알아두어야 하는 용어

SQL의 기능에 따른 분류
1. 데이터 정의어 (DDL)
- 테이블, 관계의 구조를 생성하는데 사용
- create, alter, drop 등
2. 데이터 조작어 (DML)
- 테이블에 데이터를 검색, 변경(삽입, 수정, 삭제)하는데 사용
- select(검색), insert(삽입), delete(삭제), update(변경)
3. 데이터 제어어 (DCL)
- 데이터의 사용 권한을 관리하는데 사용
- grant(권한 부여), revoke(권한 취소)
스키마 및 카탈로그 개념
- 스키마: 동일한 데이터베이스에 속해 있는 관련된 테이블 및 구성요소들의 그룹을 지칭
- 스키마의 구성요소: 테이블, 제약조건, 뷰, 도메인 등
- 시스템 카탈로그: 스키마들의 모음으로 데이터베이스의 모든 메타데이터를 관리
예시 데이터베이스, 관계형 스키마

SQL을 사용해 데이터를 검색하는 과정

데이터 조작 언어, 검색
- select, from, where





- 대표적인 3가지

- 모두 검색

- 컬럼 이름 변경

- 중복 제거

- where 절에 조건으로 사용 가능한 술어

















- group by: 튜플 결과를 부분 집합(혹은 그룹)으로 나눔, 각 그룹에 대해 집계함수를 독립적으로 적용


- having: 그룹 선택 조건 명시

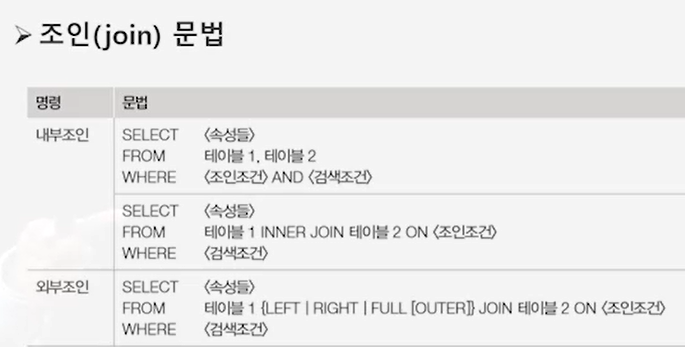
- 조인: 두 개 이상의 테이블을 특정 조건에 따라 결합시키는 연산, 기본적으로 한 테이블의 기본키와 다른 테이블의 외래키에 대한 일치 조건을 지정


- n차 조인

- 외부 조인: 조인에 참여하지 않은 튜플까지 결과에 포함시키는 연산


- 하위 질의


- exists: 조건에 맞는 튜플이 존재하면 결과에 포함시킴

- not exists: 하위 질의문의 모든 행이 조건에 만족하지 않을 때만 참

데이터 정의 언어 (DDL)
1. create table
2. alter table
3. drop table
create table
- 테이블을 구성하는 문
- 속성과 속성에 관한 제약을 정의하는 문
- 기본키와 외래키를 정의할 수 있는 문

- 외래키 제약조건을 명시할 때는 반드시 참조되는 대상 테이블이 존재해야 함
- 외래키는 참조되는 테이블의 기본키 이어야 함
- 외래키 지정시 on delete 또는 on update 옵션은 참조되는 테이블의 튜플이 삭제되거나 수정될 때 취할 수 있는 동작을 지정해야 함
- no action은 어떠한 동작도 취하지 않음
속성의 데이터 타입 종류
- SQL의 열 데이터 타입(형)
1. 정수: integer, int, smallint
2. 실수: float, real, double
3. 문자(고정길이): char
4. 문자(가변길이): varchar, clob(긴 텍스트 문서 저장 가능)
5. 비트타입(0과1)(고정길이): bit
6. 비트타입(0과1)(가변길이): bit varying, blob(긴 바이너리값 저장 가능)
7. 날짜: date
8. 시간: time
9. 타임스탬프(날짜+시간): timestamp
10. 구간(특정기간): interval
테이블의 제약 조건 기술

데이터 정의 언어 예시

테이블 생성 완료: 커밋(commit) 실행
- 커밋하지 않고 종료시 이전에 했던 작업이 무효화될 수 있으니 반드시 베이터베이스 변경이 일어날 때마다 커밋해야 함

작업취소: rollback
- rollback 명령어 사용
alter table
- alter문은 생성된 테이블의 속성과 속성에 관한 제약을 변경할 수 있음
- 기본키 및 외래키를 변경할 수 있음
1. add, drop: 속성을 추가하거나 제거할 때 사용
2. modify: 속성의 기본값을 설정하거나 삭제할 때 사용



drop table
- 테이블을 삭제하는 명령
- 테이블의 구조와 데이터를 모두 삭제하기 때문에 사용에 주의
- 만약 테이블은 남기고 거기에 있는 데이터만 삭제하고 싶다면 delete 사용


데이터 조작 언어, 테이블 레코드 변경
1. insert
2. delete
3. update
insert
- 테이블에 새로운 튜플을 삽입하는 명령



- 한번에 하나씩 작성해야 함

- 생성하지 않은 테이블에 대한 참조 불가




- 대량적재(bulk-loading): 한꺼번에 다수의 많은 행들을 적재하는 방법

delete
- 테이블에 있는 기존 튜플을 삭제하기 위한 명령문



update
- 테이블에 있는 기존 튜플의 특정 속성 값을 갱신하기 위한 명령문


SQL 전체 문법

SQL
1. SQL은 선언적으로 데이터베이스를 정의하고 조작할 수 있게 해주는 언어
2. SQL은 데이터정의어(DDL), 데이터조작어(DML), 데이터제어어(DCL)로 구성
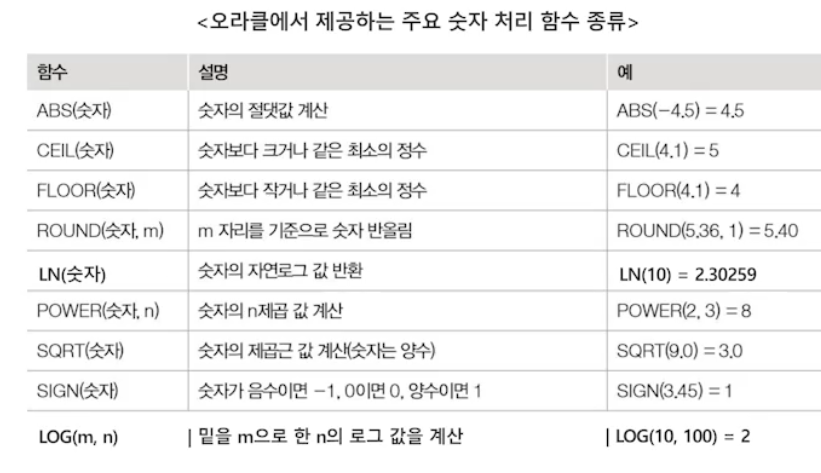
SQL 함수의 개념과 특징: 내장 함수
- 함수의 개념 사용
- 수학의 함수처럼 특정 값 혹은 열(속성)의 값을 입력받아 함수의 작업내용에 딸 해당 값을 기반으로 처리하여 최종 결과를 생산
- DBMS에서 제공하는 내장함수와 사용자 정의 함수로 나뉨
- 내장 함수는 상수나 속성 이름을 입력 값으로 받아 단일 값을 결과로 반환
- 모든 내장 함수는 유효한 입력 값을 입력으로 받아야 함











NULL 값 처리
- NULL: 아직 설정되지 않은 값
- 0, 빈문자, 공백 등과 다른 특수한 값을 나타냄
- 비교연산 수행 불가
- NULL 값의 연산을 수행하면 결과 역시 NULL 값으로 반환
NULL 값의 의미
1. 잘 모름, 아직 모름
2. 아직 이용 가능하지 않음, 현재는 없지만 나중에 있을 수도
3. 아예 적용 불가능
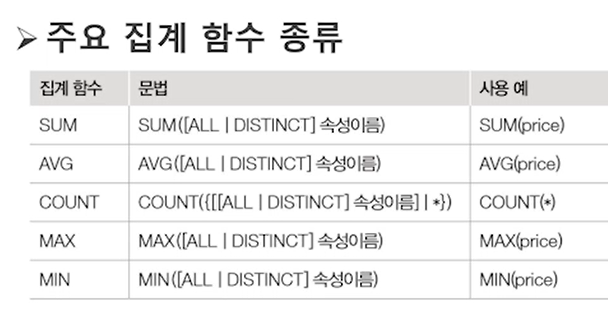
집계함수를 사용할 때 주의점
- NULL + 숫자 = NULL
- 집계함수 계산 시 NULL이 포함된 행은 집계에서 빠짐
- 해당되는 행이 하나도 없을 경우
1. sum, avg의 결과는 NULL
2. count의 결과는 0
- is null, is not null: NULL(NOT NULL)인지 검사
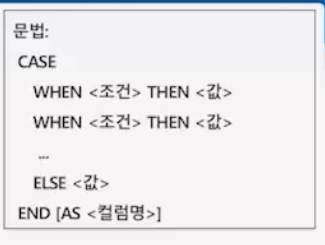
다중 조건 지정: case when
- 어떤 조건을 기반으로 어떤 값이 달라질 수 있을 때 사용
- 값이 지정될 수 있는 SQL의 어느 부분이나 사용 가능
- 튜플 검색, 삽입, 갱신 등에 적용 가능

하위 질의
1. 스칼라 하위 질의: select 하위 질의
2. 인라인 뷰 질의: from 하위 질의
3. 중첩 질의: where 하위 질의
- 하나의 SQL 안에 다른 SQL 문이 중첩된 질의를 뜻함
- 사용이유: 다른 테이블에서 가져온 데이터로 현재 테이블에 있는 정보를 찾거나 가공할 때 사용
- 성능상의 이점: 보통 데이터가 대량일 때 데이터를 모두 합쳐서 연산하는 조인보다 필요한 데이터만 찾아서 공급해주는 하위 질의가 성능이 더 좋음
- 구성: 외부질의 + 하위 질의


중첩 질의, where 하위 질의
- where 절은 보통 데이터를 선택하는 조건, 즉 술어와 같이 사용, 그래서 중첩질의를 술어 하위질의라고도 부름


집합: in, not in
- in 연산자는 주 질의 속성값이 하위 질의에서 제공한 결과 집합에 있는지 확인하는 역할
- in 연산자는 하위 질의의 결과 다중 결과 행을 반환할 수 있음
- 주 질의는 where절에 사용되는 속성 값을 하위 질의의 결과 집합과 비교해 하나라도 있으면 참이 됨
- not in은 이와 반대로 존재하지 않으면 참이 됨

한정: all, some(any)
- all은 모두, some(any)는 어떠한이라는 의미

exists, not exists
- 데이터가 존재하는지(하지 않는지)를 확인하는 연산자
- 외부(주) 질의에서 내부 질의로 제공된 속성값을 이용하여 내부 질의에 조건을 만족하여 값이 존재하면(하지 않은) 참이 되고 외부(주) 질의는 해당 데이터를 출력

스칼라 하위 질의
- select절에서 사용되는 하위 질의
- 하위 질의의 결과값을 단일 행, 단일 열의 스칼라값으로 반환
- 스칼라 하위 질의는 원칙적으로 스칼라값이 들어갈 수 있는 모든 곳에 사용 가능
- 일반적으로 select문과 update set절에 사용
- 외부 질의와 내부 질의와의 관계는 상관이든 아니든 모두 가능

인라인 뷰
- from절에서 사용되는 하위 질의
- 테이블 이름 대신 인라인 뷰 하위 질의를 사용하면 보통의 테이블과 같은 형태로 사용 가능
- 하위 질의 결과 반환되는 데이터는 다중 행이거나 열이어도 됨
- 다만 가상의 테이블인 뷰 형태로 제공되므로 상호연관 하위 질의로는 사용 x

'공공 데이터 교육' 카테고리의 다른 글
| 공공 데이터 11일 (0) | 2021.07.01 |
|---|---|
| 공공 데이터 10일 (0) | 2021.07.01 |
| 공공 데이터 8일 (0) | 2021.06.27 |
| 공공 데이터 4-7일 (0) | 2021.06.23 |
| 공공 데이터 3일 (0) | 2021.06.18 |



