컴퓨터
- 1940년대에 탄생
1. calculator = 전자 계산기
2. computing machine = 계산 기계, ACM = 가장 유명한 컴퓨터 학회
3. computer = 좀 더 단순한 기계
4. computing system = 구성 요소들이 서로 협력하는 동적인 실체
- 컴퓨터는 데이터를 처리하는 전자기기이고 데이터를 사람들에게 유용한 정보로 변환한다
- data to information
데이터 사이언스
- 정제된 지식과 통찰
- 2002, beginning of the digital age
- 데이터로부터 정제된 지식과 통찰을 추출해내기 위해 과학적 방법론, 처리과정, 알고리즘, 시스템을 사용하는 학제간 융합 분야
- 데이터 마이닝, 빅데이터
컴퓨터의 구성
1. hardware
2. sofware
3. data
4. user
컴퓨터의 프로세스
1. input
2. processing
3. output
4. storage
2진수
- on, off
- 0 또는 1
- bit
바이트
- 8 비트
단위

워드
- 1 word = 32 bit, 4 byte = 32 bit computer
- 1 word = 64 bit, 8 byte = 64 bit computer
폴더
- 정확한 명칭은 디렉토리
- 폴더라는 명칭은 윈도우에서 부르는 디렉토리
데이터 베이스 엔진
- 데이터 베이스 내용에 대한 접근과 수정을 지원하는 소프트웨어
데이터 베이스 스키마
- 데이터 베이스에 저장된 데이터의 논리 구조와 사양, 일종의 설계도
데이터 베이스 쿼리
- 데이터 베이스에서 데이터를 검색 요청, 일종의 질문 방법

데이터 베이스 용어
1. record = row = 행
2. field = column = 열
네트워크

- 웹 클라이언트 = 웹 페이지를 요청하는 컴퓨터
- 웹 서버 = 웹 페이지를 보여주는 컴퓨터
html and css
- 하이퍼텍스트 마크업 랭귀지: 웹페이지를 생성하거나 제작하기 위해 사용되는 언어
- 마크업 랭귀지: 문서에서 정보에 주석을 달기 위해 태그를 사용하는 언어
- 태그: 마크업 언어에서 정보가 표시되는 방식을 지정하는 문법적 요소
xml
- 사용자가 문서의 내용을 기술할 수 있게 해주는 언어
- html이 문서가 어떻게 보여야하는지를 기술한다면 xml은 문서의 의미를 기술
- 메타 랭귀지
웹서버 구조
- 3티어 구조
1. web server
2. was server
3. db server

데이터 분석
- 저장된 데이터에서 의미있는 정보를 얻기 위한 과정
- 데이터 분석의 목표 = 경제적 목표가 최우선
- 데이터를 활용하여 경제적 가치를 창출
1. 업무 생산성 향상
2. 고객 맞춤형 마케팅
3. 의사결정 능력 향상
4. 신사업 창출
데이터 분석의 역할
1. 불확실성 해소 - 통찰력 제공
2. 위험 감지와 회피 - 대응력 제공
3. 스마트 경제 도입 - 경쟁력 상승
4. 융합 기술 도입 - 창조력 향상
데이터 분석 과정
1. 문제 정의
2. 데이터 수집
3. 데이터 가공(전처리)
4. 데이저 저장, 관리
5. 데이터 분석
6. 데이터 가시화
7. 데이터 공유
8. 지식 활용
데이터 플랫폼
1. 데이터 수집 플랫폼
- 데이터 검색, 데이터 수집과 변환
- 크롤링
2. 데이터 저장 플랫폼
- 데이터 실시간 저장과 활용
- 하둡 분산형 파일 시스템
3. 데이터 처리 플랫폼
- 초고속 병렬 처리, 데이터 가공과 추출
- 스파크, 스톰
4. 데이터 관리 플랫폼
- 효율적이고 정확한 데이터 분석
- 통계분석, 최적화
데이터 문제 정의
- 문제 정의의 중요성, 아인슈타인: 55분 문제 동안 대해 생각하고 5분 동안 해결책 생각
- 과학과 공학의 차이
1. 과학 = 최선책, 최고의 해답을 추구
2. 공학 = 현실적 해답 제시, 적절하고 최소비용으로 해결
- 필요한 데이터와 접근 방법 파악 가능
문제 정의 시의 필수 고려 사항
1. 문제의 목표 정의 - 문제의 목표가 무엇인가?
2. 문제 범위 결정 - 문제의 범위는 정확히 어디까지?
3. 문제 결과에 대한 성공 기준 - 문제 해결의 성공/실패 기준은 무엇인가?
4. 문제 해결의 제약 조건 - 문제 해결에 필요한 시간/비용은 얼마인가?
데이터 분석의 목표
1. 현상의 이해
2. 현상의 일반화
3. 현상의 예측
데이터 수집
- 서비스 활용에 필요한 데이터를 시스템의 내부 혹은 외부에서 주기성을 가지고 필요한 형태로 수동 또는 자동으로 수집하는 활동
1. 데이터 선정
2. 데이터 위치 파악
3. 데이터 수집 방법 적용
4. 데이터 수집 진행
데이터 수집 계획서
1. 데이터 소스의 명시
2. 수집 주기
3. 수집 방법
수집 데이터의 유형


open api
- 데이터 수집 방법의 일종
- api: 프로그래밍 언어에 제공되는 인터페이스 방식, 클라이언트가 자료 호출하면 서버가 자료를 알려주는 방식
- 여러 사람들이 공동 사용할 필요가 있는 데이터에 대한 사용을 개방
- 사용자들이 해당 데이터에 대한 전문지식이 없어도 쉽게 가공하여 사용가능
- 데이터를 추상화하여 표준화한 인터페이스
- xml, json 형식을 많이 사용

데이터 전처리

- 쓰레기를 넣으면 쓰레기가 나오는 데이터 분석
데이터 품질 저해 요소
1. 노이즈 - 측정 과정에서 무작위로 발생한 측정값 에러
2. 아티팩트 - 특정 요인으로 발생하는 반복적 왜곡/에러
3. 이상치 - 다른 개체와 다른 유별난 값의 출현, 중요한 데이터일 가능성도 존재
4. 결측치 - 자료 입력이 누락되거나 고의로 빠진 경우
5. 모순, 불일치
6. 중복
결측치 처리

잡음 처리

데이터 전처리의 단계
1. 데이터 정제
2. 데이터 통합
3. 데이터 변환
4. 데이터 축소

메타 데이터
- 데이터에 관한 구조화된 데이터
- 다른 데이터를 설명하는 데이터
1. 기술용 메타 데이터 - 정보 자원의 검색을 목적으로 하는 메타 데이터
2. 관리용 메타 데이터 - 자원 관리를 용이하게 하기 위한 메타 데이터
3. 구조용 메타 데이터 - 복합적인 디지털 객체들을 묶어주기 위한 메타 데이터
개체 식별 문제
- 여러 데이터 소스를 하나로 통합할 때 발생
- 동일한 의미의 개체들을 서로 다르게 표현하고 있을 수 있음
- 메타 데이터 활용이 중요
데이터 파이프라인
- ETL, 변환 후 저장 개념이기에 저용량 처리에 적합하며 실시간 처리가 어려움
1. extract
2. transform
3. load
- ELT, 클라우드로 가능해짐, 일단 저장하고 나중에 변환한다는 개념
1. extract
2. load
3. transform
네트워크 스토리지
1. DAS
2. NAS
3. SAN
4. SDS





데이터 웨어하우스
- 관계형 db를 근간으로 많은 데이터를 다차원 분석하여 의사결정에 도움을 주는 시스템
1. 주제중심적
2. 비휘발성
3. 통합적
4. 시간가변적
데이터 레이크
- 대용량의 정형 및 비정형 데이터를 원시형태 그대로 저장하고 손쉽게 접근할 수 있게하는 대규모 저장소
데이터 분석 방법론
1. 단계
2. 태스크
3. 스텝
분석방법론 적용 모델
1. 폭포수
2. 프로토타입
3. 나선형
데이터 분석 방법
1. 묘사적 데이터 분석
- 현재의 모습을 요약하여 기술
- 수집된 데이터의 표현
- 평균, 표준편차, 빈도수, 백분위수
2. 탐색적 데이터 분석
- 수집된 데이터의 증상 탐색을 통한 가설 도출
- 가능성이 큰 x-y 관계 가설 도출
3. 확증적 데이터 분석
- 도출된 가설을 검증
- p-value 기준 의사결정
4. 예측 데이터 분석
- 관계식을 만들고 최적 조건을 예측
- 의미 있는 y=f(x) 함수식 모델 도출
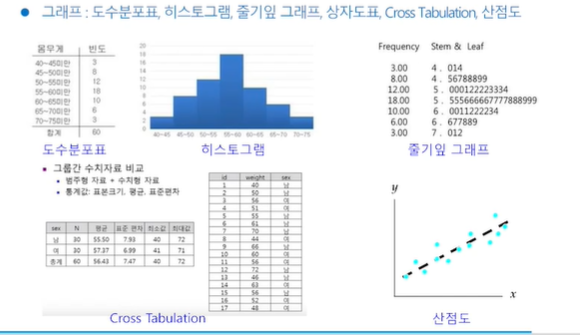
기술통계와 추론통계

범주형 데이터의 기술통계분석

수치형 데이터의 기술통계분석




데이터 타입
1. 문자
2. 숫자
3. 이미지
4. 오디오
5. 비디오
- 모든 데이터는 2진수 형태로 자료를 저장
압축
- zip은 무손실 복원 가능 = 비손실 압축 기법
- jpeg로 바꿔도 인간의 눈으로 큰 차이 x = 손실 압축 기법
ASCII
- 128 unique characters = 영어 소문자+대문자, 숫자, 기호 등
- 7비트
- extended ASCII는 8비트
Unicode
- 16비트 = 65536
한글 코드 체계
- 초성 19자, 중성 21자, 종성 28자
- 모든 조합 = 19*21*28 = 11172자 = Unicode/UTF-16에 할당
정규화 방식
1. NFC = 한글의 자음/모음을 결합해서 저장, 윈도위/리눅스 등에서 사용
2. NFD = 한글의 자음/모음을 분리해서 저장, 맥에서 사용
이미지
1. 흑백 - 1픽셀 = 1비트
2. 그레이스케일 - 1픽셀 = 8비트
3. 컬러 - 1픽셀 = 24비트
resolutions

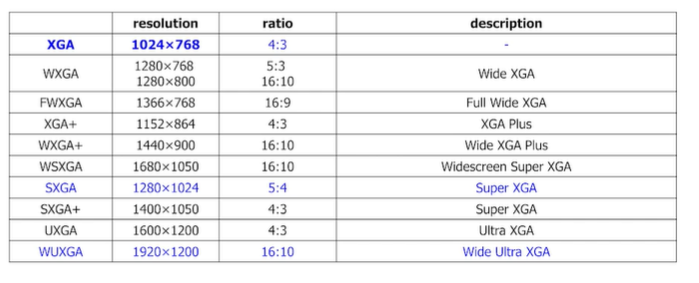

이미지 저장




오디오


샘플링 비율

비디오
- 1초에 30장 이상 필요
- MPEG 압축 기술이 대표적




