- 1주 -
3회 결석 시 F처리
중간고사, 기말고사 하나라도 응시하지 않을 경우 F처리
컴퓨터의 4대 기능
1. 입력
2. 출력
3. 처리
4. 저장
비트
- 정보를 구성하는 최소 단위
- 0과 1 두가지 중 하나를 나타냄
바이트
- 정보를 구성하는 기본 단위
- 8개의 비트 (256가지 정보를 저장 가능)
워드
- 바이트 보다 큰 단위
- cpu에서 한번에 처리할 수 있는 비트의 개수
- 64bit 컴퓨터는 8byte를 1word로 사용
중앙처리장치(cpu)
- 컴퓨터 시스템의 모든 장치를 제어/명령/실행
- 제어장치 + 연산장치 + 레지스터 + cpu 내부 버스 등
1. 제어장치
- 명령 인출 및 해독, 제어신호 전달
2. 연산장치
- cpu 내부에서 데이터를 처리하는 장치
- 실행장치 또는 산술논리장치라고도 부름
3. 레지스터
- 데이터를 처리하는 동안 사용할 값이나 중간 결과를 일시적으로 저장
- 다양한 레지스터가 존재
코어
- 프로세서 칩에 포함된 각각의 처리 유닛
프로세서
- 하나 이상의 코어를 담고 있는 물리적인 실리콘 조각
속도
1. 레지스터
2. 캐시 메모리
3. 메인 메모리(ram)
4. 보조기억장치
캐시 메모리
- 프로세서와 메인 메모리 사이에 여러 단계로 구성된 메모리
- 메인 메모리 보다 작지만 빠름
- 캐시를 여러 단계로 구성하면 극적으로 속도가 빨라질 수 있음
- 향후 사용될 것이라고 생각되는 데이터를 메인 메모리부터 미리 가져다 놓음으로써 속도 향상
- L1, L2, L3 등의 캐시 이름에서 L은 단계를 의미하며 숫자가 작을 수록 코어에 가까운 캐시
시스템 버스
- 데이터 버스 = cpu와 메인 메모리, 주변장치 사이에 데이터 전송
- 주소 버스 = cpu가 시스템 요소를 식별하기 위한 주소 정보 전송
- 제어 버스 = cpu가 시스템 요소의 동작을 제어하기 위한 신호 전송
메인보드
- 컴퓨터 실행 환경 설정, 설정 정보 유지, 안정화 등을 담당
- 노스브릿지에서 메모리 컨트롤, 사우스브릿지에서 io 컨트롤
architecture
- 프로그래머에게 보이는 시스템의 속성
- 프로그램의 논리적 실행 흐름에 직접 영향을 줌
organization
- 프로그래머에게 보이지 않는 하드웨어적 세부 사항
- 구조에서 정의한 사항들을 구현하기 위한 연산 유닛과 상호 연결 방식을 의미
-----------
- 2주 -
컴퓨터 = 계산기
0세대 컴퓨터, 기계식 계산기
- 파스칼 계산기
- 라이프니츠 계산기
- 차분기관
1세대 컴퓨터, 진공관 컴퓨터
- 콜로서스, 세계 최초의 디지털 컴퓨터
- 애니악
2세대 컴퓨터, 트랜지스터 컴퓨터
- IBM 7030 stretch
3세대 컴퓨터, 집적회로 컴퓨터
- Altair 8800
4세대 컴퓨터, 초고밀도 집적회로 컴퓨터
- IBM pc 5150
5세대 컴퓨터
- IBM watson
폰노이만 머신
- 진공관 컴퓨터인 애니악에서는 프로그램을 저장하고 변경하는 일이 번거로움
- 만약 프로그램이 데이터와 함께 기억장치에 저장될 수 있다면 프로그래밍이 더욱 쉬어질 것으로 판단
- 저장된 프로그램 개념 등장 (stored program concept)
- 해당 개념을 바탕으로 IAS라는 컴퓨터를 개발
- IAS는 이후 개발된 모든 범용 컴퓨터의 원형 모델
IAS 컴퓨터의 명령 구조
- 1000개의 저장소를 가지고 있으며 각 저장소에는 40비트로 구성된 워드가 존재
- 데이터와 명령어는 모두 워드에 저장
- IAS는 저장된 명령을 순서대로 하나씩 수행
레지스터의 종류 (중요)
1. MBR
- 메모리에 저장할 워드나 메모리에서 읽어온 워드를 저장
2. MAR
- MBR이 쓰여지거나 읽어올 워드의 메모리 주소를 저장
3. IR
- 실행할 명령어의 8bit 연산 코드를 저장
4. PC
- 다음에 읽을 메모리 주소를 저장
5. AC
- 계산에 사용할 데이터나 ALU의 연산 결과를 일시적으로 저장
프로그램의 실행의 주요요소
1. fetch = 기억장치로부터 한번에 한개씩 명령어를 읽어 옴
2. execute = 읽어온 명령어를 실행함
컴퓨터의 기능
1. 컴퓨터의 기능? = 프로그램을 실행하는 것
2. 프로그램이란? = 명령어들의 집합으로서 명령어 처리를 반복하는 것
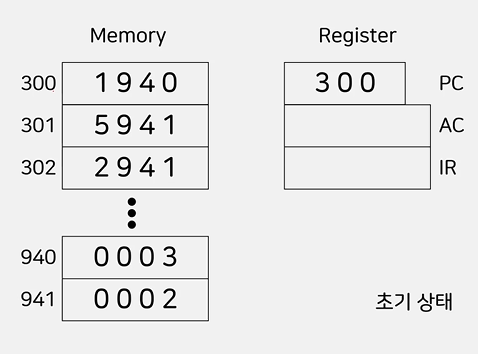
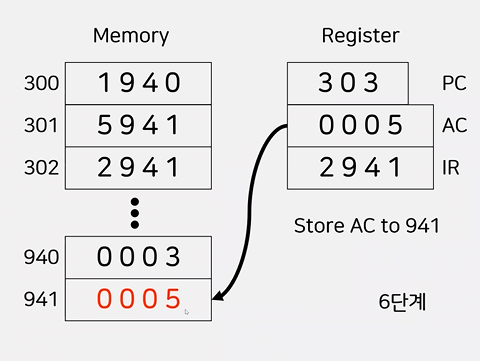
명령어의 인출과 실행 예제
- 워드의 크기에 대해 통일된 정의 x
- 현 강의에서는 1워드를 16bit으로 가정
- 명령어는 4bit 옵코드와 12bit 주소로 구성
- 가상의 컴퓨터에서 처리할 수 있는 명령과 그에 해당하는 Opcode의 2진수 값은 다음과 같다.
- 0001: 16진수 1, (Operand에 명시된 메모리 주소로부터 데이터를 읽어서 AC에 적재한다.
- 0010: 16진수 2, AC에 저장된 데이터를 Operand에 명시된 메모리 주소에 저장한다.
- 0101: 16진수 5, Operand에 명시된 메모리 주소로부터 데이터를 읽어서 AC에 저장된 값과 더한 후, 다시 AC에 저장한다.
- 0011: 16진수 3, Operand에 명시된 번호의 입출력 장치로부터 데이터를 읽어서 AC에 적재한다.
- 0111: 16진수 7, AC에 저장된 데이터를 Operand에 명시된 번호의 입출력 장치에 저장한다.





---------------
- 3주 -
컴퓨터 = fetch와 execute를 반복하는 기계
폰노이만 기계의 특징
1. stored program concept
2. AIS structure
3. sequential execution of intstructions one by one
fetch + execute = instruction cycle
인터럽트
- 거의 모든 컴퓨터들은 다른 모듈의 처리 과정을 방해할 수 있는 방법을 제공
- 인터럽트는 주로 처리 효율 향상을 위해 사용
외부인터럽트 vs 내부인터럽트
- 외부
1) 정전, 기계 결함과 같은 외적 요인
2) 입출력을 요구하는 입력장치 등에 의해 발생
3) 사용자의 제어, 타이머에 정해진 시간이 경과
4) 사용자나 다른 프로세서에 의해
- 내부
1) cpu 내부에서 발생
2) exception: 프로그램 오류로 발생 (0으로 나누기, 메모리 보호 영역 접근, 정의되지 않은 명령어, 오버플로 등)
3) trap: 소프트웨어 인터럽트, 명시적으로 예외조건을 생성하여 발생 (디버깅 같은 서비스, 고의적으로 슈퍼바이저 모드로 진입 등)
인터럽트의 우선순위
1) 정전
2) 기계 오작동
3) 입출력
4) exeption
5) trap
인터럽트 처리
- 인터럽트를 처리하는 루틴을 인터럽트 서비스 루틴 또는 인터럽트 핸들러라 부름
인터럽트의 일반적인 처리과정
1. 인터럽트의 요청 신호 검출
- 모든 명령 사이클마다 한번씩 인터럽트 요청 여부 검사
2. 인터럽트 우선순위 제어 및 허용여부 판단
- 인터럽트 요청이 있다면 인터럽트 확인 신호를 보내고 요청 장치 식별
- 인터럽트 확인 신호를 받은 장치는 인터럽트 요청 신호 제거
- 인터럽트 마스크 레지스터를 사용하여 인터럽트 허용여부 판단
- 다수의 인터럽트가 있다면 우선순위에 따라 허용
3. ISR 시작 번지 확인
- 인터럽트 벡터 테이블을 사용하여 인터럽트를 요청한 입출력장치에 대응하는 ISR 시작 번지 확인
4. 복귀 주소 및 레지스터 저장
- ISR을 종료하고 돌아올 수 있도록 현재 PC값을 스택에 저장
- ISR이 레지스터를 사용할 경우 현재 레지스터도 스택에 저장
- 처리도중 하위 수준 인터럽트를 막기 위해 인터럽트 마스크 설정
- PC값을 ISR의 시작 주소로 변경
5. ISR 실행
- ISR로 분기하여 프로그램 실행
6. 인터럽트 된 프로그램으로 복귀
- ISR 실행이 종료되면 스택에서 PC값, 레지스터를 복원
- 인터럽트 마스크 레지스터도 원상태로 복원
- 인터럽트된 프로그램을 다시 실행
인터럽트 요청장치를 식별하는 방법
- 모든 입력장치마다 별개의 인터럽트 라인을 사용하면 쉽게 식별 가능
- 하지만 cpu칩은 핀 수가 제한적이므로 제한된 수의 장치만 연결 가능
해결방법
1. 모든 입출력장치가 하나의 인터럽트 라인을 공유 (폴링)
2. 인터럽트 라인을 다중화
일반적인 IO프로그램은 3가지 영역으로 구성
1. IO동작을 준비하는 일련의 명령
2. 실제 IO명령
3. 동작을 종료하기 위한 일련의 명령
인터럽트가 포함된 명령어 사이클
- 인터럽트 사이클에서 프로세서가 인터럽트 신호를 체크
- 대기 중인 인터럽트가 없다면 fetch cycle로 이동
- 대기 중인 인터럽트가 있다면
1) 현재 프로그램 실행을 중단하고 context를 저장, context에는 다음 명령의 주소 + 프로세서의 현재 동작 관련 데이터 등이 포함
2) pc에 인터럽트 핸들러 루틴의 시작주소를 세트하고 fetch cycle로 이동
다중 인터럽트
1) 인터럽트가 순차적으로 처리되는 경우
- 하나의 인터럽트가 처리되는 동안 다른 인터럽트를 무시
- 무시된 인터럽트는 대기 상태(pending)로 존재
2) 인터럽트가 중첩된 경우
- 인터럽트를 처리하는 도중 우선순위가 높은 또 다른 인터럽트가 발생하면 현재 인터럽트 처리를 일시 중단하고 다른 인터럽트를 우선 처리
용어정리 (memory)
1. 단어(word)
- 기억장치를 구성하는 기본 단위
- word의 길이는 일반적으로 수를 표현하기 위해 사용되는 비트의 수 또는 명령어의 길이와 동일 (예외도 존재)
2. 주소지정단위 (addressable units)
- 대부분의 시스템에서 주소지정이 가능한 단위는 word
- 일부 시스템은 바이트 단위로 주소지정이 가능
3. 전송단위 (unit of transfer)
- 주기억장치 입장에서 한번에 읽고 쓸 수 있는 비트의 수
- word나 주소지정 단위와 일치할 필요는 없음
- 외부 기억장치는 word보다 더 큰 블록 단위로 전송
용어정리 (access method)
1. 순차적 접근
- 기억장치는 레코드라고 하는 데이터 단위로 구성되며 접근이 특정 순서에 따라 이루어짐
- 주소정보는 레코드를 구분하기 위해 사용
- 현재 위치로부터 원하는 위치로 이동하여 읽기/쓰기 수행
- 저장된 위치에 따라 접근시간이 크게 달라짐
- 테이프는 순차적 접근 방식을 사용
2. 직접 접근
- 순차적 접근과 비슷
- 다만 각 레코드나 블록이 물리적 위치에 따라 유일한 주소를 가지고 있음
- 원하는 데이터의 주소로부터 가까운 곳에 접근한 후 순차검색, 계수, 대기 등을 통해 데이터에 접근
- 디스크는 직접 접근 방식 사용
3. 임의 접근
- 기억장치 내의 각 위치는 선들로 연결된 별도의 주소지정 메커니즘을 가지고 있음
- 어떤 위치에 접근하던지 걸리는 시간은 항상 일정
- 따라서 어떤 위치라도 임의로 선택하여 직접 주소지정 후 접근할 수 있음
- 메인 메모리와 캐시 메모리가 임의 접근 방식 사용
4. 연관 접근
- 임의 접근 기억장치의 일종으로 word 내의 특정 비트들과 원하는 비트들을 비교하여 일치하는 word에 접근
- 비교동작을 모든 word에 대해 동시에 수행할 수 있음
- 다른 임의 접근 기억장치들과 마찬가지로 각 위치는 자신의 주소지정 메커니즘을 가지고 있음
- 검색에 걸리는 시간은 위치에 상관없이 동일
- 특수한 캐시 기억장치에 연관 접근 방식을 사용
용어정리 (performance)
1. 접근시간
- 임의 접근 기억장치의 경우 (반도체 메모리) 읽거나 쓰는 동작을 수행하는데 걸리는 시간을 의미, 주소가 기억장치에 도착하는 순간부터 데이터가 저장되거나 읽혀지는 순간까지의 시간
- 비임의 접근 기억장치의 경우 (비반도체 메모리) 원하는 섹터 위치로 헤드의 위치를 이동하는데 걸리는 시간
용어정리 (physical property)
1. 휘발성 기억장치
- 정보가 자연적으로 소멸되거나 전력 공급이 중단되면 사라짐
- ram
2. 비휘발성 기억장치
- 일단 기록된 정보는 필요에 의해 변경될 때까지 그대로 유지
- 정보를 보관하는데 전력이 필요 x
- rom, 디스크, 테이프
메모리 설계의 중요 요건
- 용량, 속도, 가격
1) 엑세스 속도가 빨리질수록 비트당 가격이 높아짐
2) 용량이 커질수록 비트당 가격이 낮아짐
3) 용량이 커질수록 엑세스 속도는 느려짐
- 세가지 주요 특성들 사이에는 적절한 상호조정 필요
- 신기술을 만드는 것이 아닌 메모리 계층구조를 통해 해결
메모리 계층구조
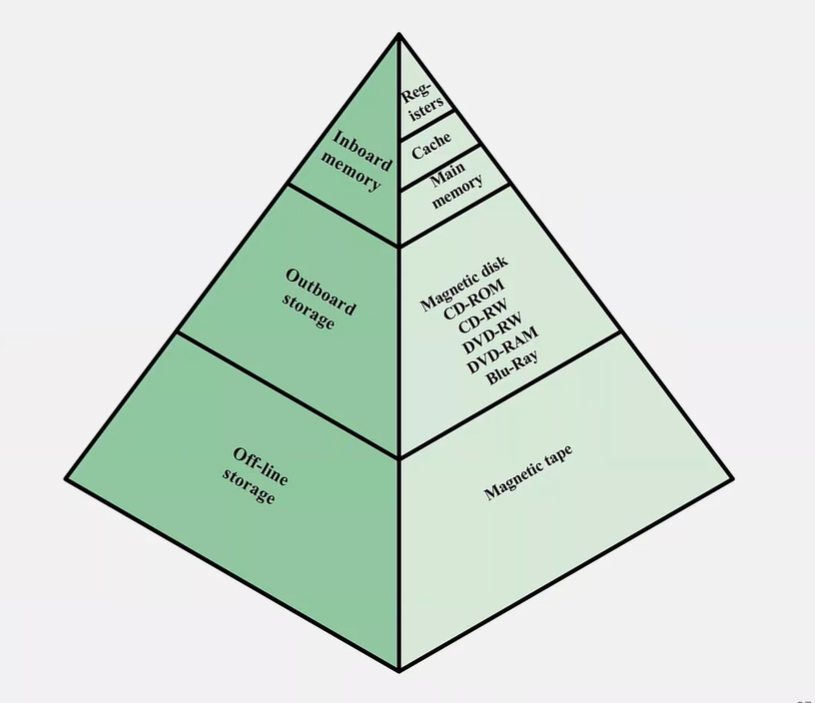
- 지역성 원리
1) 컴퓨터 프로그램은 주소 공간의 일부를 일정시간 동안 그룹 형태로 참조하는 경향이 있음
2) 프로그램의 10% 미만이 실행 시간의 90% 이상을 차지한다고 알려짐
3) 이런 경향성을 지역성 원리 또는 참조의 지역성이라 부름

시간의 지역성
- 최근 참조된 명령어나 데이터가 가까운 미래에 다시 참조되는 경향
공간의 지역성
- 최근 참조된 명령어나 데이터의 이웃이 가까운 미래에 참조되는 경향
메모리 계층에 따른 전송단위
1) cpu - 캐시메모리 = 워드
2) 캐시메모리 - 메인메모리 = 블록(라인)
3) 메인메모리 - 보조기억장치 = 페이지
----------------
- 4주 -
캐시메모리
- cpu와 메인메모리 사이에 존재
- 메인메모리에 저장된 데이터를 빠르게 사용할 수 있도록 도와주는 작은 크기의 고속 메모리
- 곧 cpu가 사용할 것이라고 예상되는 데이터의 일부를 메인메모리로부터 미리 가져옴
- cpu는 캐시가 하는 일에 대해 인지하지 못함
캐시
- tag + line
- 캐시의 한 line = 메모리의 한 block
- 메인메모리에 여러 워드가 모여 하나의 블록을 이룸
- tag에는 메인메모리의 여러 블록 중 어느 블록을 가지고 왔는지에 대한 정보가 숫자로 적혀 있음
캐시의 동작
- RA를 보고 그 데이터가 캐시에 있다면 cpu에게 바로 전달 (캐시 hit)
- 데이터가 없다면 캐시에 데이터를 저장하고 cpu에게 전달 (캐시 miss)
캐시 설계는 히트율을 높이는 것이 관건
- 사용시스템은 약 75%
- 한번 사용한 것을 가져다 놓는 것과 히트율의 관계 = 참조의 지역성
캐시의 3가지 맵핑 방식
- 공통조건
1) 메인 메모리의 크기는 16mb
2) 캐시의 크기는 64kb
3) 블록의 크기는 4byte
- 계산 문제
1) 메인 메모리는 몇개의 블록으로 구성되어 있는가? = 2의 24승 / 2의2승 = 2의22승
2) 캐시는 몇개의 라인으로 구성되어 있는가? = 2의16승 / 2의2승 = 2의14승
3) 메인메모리는 캐시의 몇배인가? = 2의22승 / 2의14승 = 2의8승
캐시의 3가지 맵핑방식
1) 직접사상방식
- 메인메모리를 여러개의 논리적프레임으로 나눔
- 하나의 프레임은 캐시메모리와 동일한 크기로 구성
- 프레임 속 블록 번호와 동일한 캐시라인에 데이터를 저장
2) 연관사상방식
- 프레임이 없음
- 태그에는 블록번호가 들어옴
- 회로가 비싸고 태그로 인한 부담이 큼
3) 세트연관사상방식
- 앞서 언급한 두가지 방식의 혼합
- 캐시를 k개의 라인으로 구성된 v개의 세트로 재구성
예제)
컴퓨터 구성요서의 크기
1) 메인메모리 = 512바이트
2) 캐시메모리 = 128바이트
3) 블록크기 = 16바이트
4) 워드크기 = 4바이트
- 메모리에 포함된 블록의 개수 = 메인메모리 / 블록크기 = 32 = 2^5 = 5바이트
- 캐시의 라인 수 = 캐시메모리 / 블록크기 = 8 = 2^3 = 3바이트
- 메모리는 캐시의 몇배? = 메인메모리 / 캐시메모리 = 4배
- 블록 내 워드의 수 = 블록크기 / 워드크기 = 4 = 2^2 = 2바이트
----------------------
- 5주 -
메인메모리와 cpu의 연결
- 주소를 받는 회선과 데이터를 받는 회선이 존재
- 메모리는 여러개의 메모리 소자들로 구성
cpu와 메모리는 메인보드의 노스브릿지를 이용해 연결
- cpu와 노스브릿지를 연결하는 선을 FSB라 함
cpu와 메모리가 mar, mbr을 어떻게 사용하는가?
- 워드크기 = 4비트
- 메모리크기 = 32비트
- 레지스터 1번지와 2번지의 초기값은 각각 0001, 0010
- 3번지는 0011
- 워드의 크기가 4비트이므로 mbr과 데이터버스의 크기는 4비트
- 메모리용량이 8개 워드이므로 mar과 주소버스의 크기는 3비트
내부메모리 = 메인메모리
- 반도체메모리를 이용해서 만든 저장공간
- 반도제메모리의 특성은 휘발성 혹은 비휘발성
cell
- 1비트 데이터 정보를 저장하는 기본 회로
ram
1) sram = 전원이 공급되는 중에는 데이터를 유지하는 방식
- capacitor type 형태의 cell을 사용
- capacitor는 배터리처럼 충전해서 사용하는 것
- 점점 방전되듯 정보가 점점 사라질 정도로 단순하게 구성
2) dram = 전원이 공급되더라도 시간이 지나면 데이터가 소멸되는 방식, 주기적인 refresh
- flip flop 형태의 cell을 사용
- flip flop은 정보가 내부에 저장되면 정보를 수정하지 않는 이상 데이터를 계속 유지하려는 특성
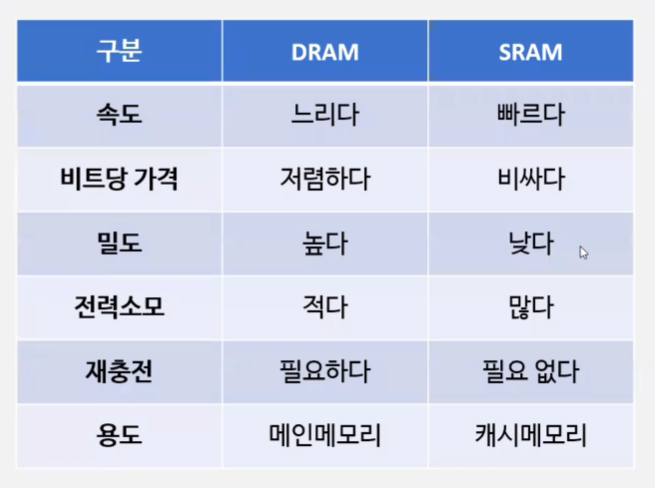
rom
- 초창기의 rom은 그냥 그대로 read only
- 데이터 입력은 제작과정에서
1) prom
- 본인이 원하는 데이터를 넣을 수 있는 rom
- 별도의 장치가 필요
2) eprom
- 집어넣은 데이터를 일부 수정할 수 있는 prom
- 수정할 때에는 자외선을 이용
3) eeprom
- 사용자 입장에서 좀 더 쓰고 지우기 쉽게 만들어진 eprom
- 비트 단위로 쓰기 지움
16m비트 dram
- 4m * 4 = 16m비트
- 뒷부분의 4는 메모리 소자 하나에 대한 워드길이로 시스템 상 한번에 이동되는 데이터 단위를 의미
- 4m은 워드의 개수가 몇개인지를 의미
- 즉 4비트짜리 워드가 4m개 있다는 의미
- 4m개 워드는 2k * 2k 정방형으로 저장
- 어드레스 지정 = 4m개 중에 하나를 고르려면 22비트가 필요, 2k * 2k로 저장되니 가로세로 각각 11비트씩 사용
핀의 구성
- 회로를 구성하려면 전원/그라운드/데이터핀/제어핀/주소핀 등이 필요
- 만일 22개의 핀을 사용한다면 물리적으로 칩이 커짐(핀마다 일정한 크기의 공간을 차지하기에)
- 또한 핀은 칩이 사용하는 전체 전력량의 60~70% 사용
- 반도체 회사들의 숙제는 핀의 수를 줄이는 것
256k*1 chip의 의미
- 워드 길이 = 1비트, 즉 한번에 1비트씩 데이터 이동
- 어드레스 필드 = 18비트, 주소를 지정하기 위해 18비트 필요, 256 = 2*8, k = 2*10, 총 2*18
- 512*512의 형태로 데이터 저장, 9비트씩 두번 주소를 저장
256k*1칩으로 256k바이트 메모리 만들기
- 우선 8비트 cpu로 가정
1) data bus
- cpu 측에서 요구하는 양 = 8비트
- 각 칩에서 제공하는 양 = 1비트
- 8개의 칩이 필요
2) address bus
- cpu 측에서 제공하는 양 = 18비트
- 각 칩이 요구하는 양 = 18비트
- cpu의 address line을 모든 칩에 연결
256k*1칩으로 1m바이트 메모리 만들기
- 필요한 칩의 개수 = 32개
1) data bus
- cpu 측에서 요구하는 양 = 8비트
- 각 칩에서 제공하는 양 = 1비트
- 32개 칩을 8개씩 4개의 그룹으로 재구성
2) address bus
- 각 칩이 요구하는 비트 수 = 18비트 (256k = 2*18)
- 4개 그룹 중 1개를 선택하기 위한 비트 수 = 2비트 (4 = 2*2)
- cpu가 제공하는 address bus의 비트 수 = 20비트 (18+2, 2비트는 그룹(뱅크)를 선택하고 18비트는 각 뱅크에 제공)
교차메모리
- 데이터 버스를 하나로 유지
- 메모리를 다수의 독립된 뱅크로 분할한 것
- 메모리를 2*n개의 뱅크로 분할하면 하나의 뱅크를 선택하기 위해 m비트가 필요
하위인터리빙
- 하위주소 m비트를 사용하여 접근할 뱅크를 선택
- 병행처리에 유리하므로 데이터를 순차적으로 사용하는 프로그램에 적합
- 공간적 지역성에 적합
- 단점: 비순차 접근 시 성능이 떨어짐, 데이터가 모든 뱅크에 분산되어 있으므로 하나의 뱅크에 오류가 발생할 경우 전체 시스템에 영향
상위인터리빙
- 상위주소 m비트를 사용하여 접근할 뱅크를 선택
- 메모리마다 2*m개의 연속된 주소를 가짐
- 메모리확장에 유리
- 뱅크에 결함이 있어도 주소공간 일부만 사용할 수 없는 것이므로 결함허용도가 높음
- 단점: 순자첩근시 성능향상 불가능, 공간의 지역성에는 부적합
-----------------------------------
-6주-
오류수정
- 정확히는 수정보다 탐지의 개념
- 한 word를 저장하기 위해 필요한 공간 = M + K
체크코드 생성
- 주어진 데이터에 특정한 함수를 적용하여 생성
parity code
- 데이터에 포함된 1-bit 오류를 검출하기 위해 사용되는 1-bit 코드
신드롬
- 미리 저장해둔 체크코드와 새로 생성한 체크코드를 비트 단위로 비교한 것 (2*k개 존재)



체크섬
- 나열된 데이털르 더하여 체크섬 숫자를 얻고 정해진 비트 수로 나눈 나머지를 사용


첨단 DRAM
- 프로세서의 성능이 좋아지더라도 내부 메모리가 따라주지 못하면 병목현상이 발생할 수 있음
- DRAM 구조는 1970년대 이후로 최근까지 큰 변화 x
- 전통적인 DRAM 칩은 내부 구조와 프로세서 기억장치 버스 사이의 인터페이스 때문에 한계가 존재
- 이를 해결하기 위해 SRAM 캐시를 사용
- 그러나 DRAM보다 훨씬 비싸기에 일정 수준 이상 캐시크기를 늘리면 가성비가 떨어짐
SDRAM
- 전통적인 비동기식 DRAM과 달리 외부 클록 신호와 동기화
- 대기 상태 없이 프로세서/기억장치 버스의 최대 속도로 실행 중인 프로세서와 데이터 교환 가능
- 시스템 클록을 이용하므로 RAS, CAS 탐지 시간이 필요 없음
- 카운터를 이용하여 열 주소를 갱신, 연속적으로 메모리 셀에 접근
DDR DRAM
- 세가지 방법으로 SDRAM의 성능 한계를 개선
1) 상승 에지 뿐만 아니라 하강 에지에도 데이터를 출력
2) 전송률을 높이기 위해 속도가 빠른 버스를 사용
3) 버퍼링 방식 이용
- 현재 DDR4까지 등장
- 초기 DDR 버전은 2비트 프리패치 버퍼를 사용
- 버전이 증가함에 따라 버퍼의 크기를 늘림
- DDR3는 프리패치가 8비트인데 4비트만 필요하면 효율 저하
- 이를 개선하고자 DDR4는 뱅크개념을 도입

플래시 메모리
- 1980년 중반에 도시바에서 발명한 플래시 메모리
- 기능면에서 EPROM과 EEPROM의 중간에 위치 (전기로 소거 가능)
- 전체 플래시 메모리를 수초 내에 지울 수 있음
- 블록단위로 삭제할 수 있지만 바이트 수준 삭제는 지원하지 않음
- 메모리 비트당 하나의 트랜지스터를 사용하므로 EEPROM에 비해 밀도가 높음
플래시 메모리의 동작
- 플래시 메모리 셀에는 플로팅 게이트라 불리는 얆은 산화물층이 트랜지스터에 추가되어 있음
- 초기상태는 1로 간주
- 큰 전압을 가하면 전자가 플로팅 게이트에 갇히게 되면서 전원이 끊기더라도 전자가 남게 됨, 이 상태를 0으로 간주
- 반대 방향으로 큰 전압을 가하면 플로팅 게이트에서 전자가 제거되고 다시 1인 형태로 돌아감
NOR vs NAND
1) NOR flash
- 인텔에서 최초 상용화
- 셀이 비트 라인에 병렬로 연결되어 각 셀을 개별적으로 읽고/쓰고/지울 수 있음
- 지우기와 쓰기 시간이 긴 대신 어떤 위치에도 접근할 수 있도록 주소/데이터 인터페이스를 제공
- BIOS, 펌웨어 등 거의 수정하지 않는 프로그램 코드 저장에 용이
2) NAND
- 16개 또는 32개의 트랜지스터를 직렬로 연결
- NOR 방식에 비해 기록 및 삭제 시간이 짧고 칩 밀도가 높아서 저비용/대용량화 가능
- 데이터 접근을 위한 입출력 인터페이스만 지원하므로 대용량 저장장치로 사용


